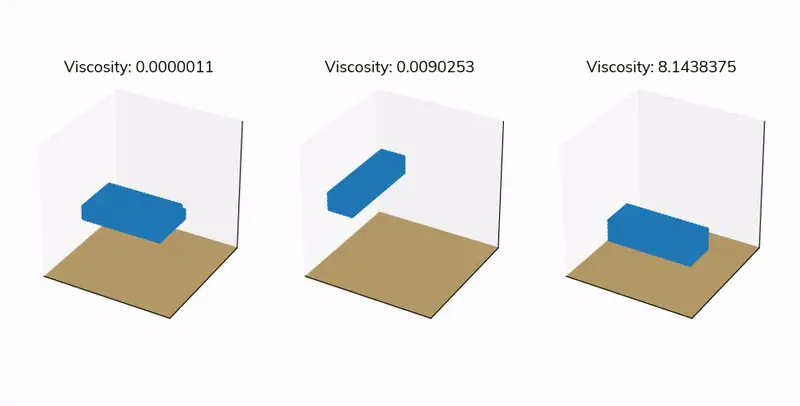
Looking for a dataset to get you started with fluid dynamics simulations? Our Fluid Cube dataset contains 100 unique fluid simulations, each capturing the movement of a fluid block within a unit cube. In every simulation, the fluid block is assigned a different initial shape, position, velocity, and viscosity, providing a variety of scenarios to study.
This dataset is perfect for researchers and engineers looking to understand how fluids behave under different physical conditions, test machine learning algorithms for predicting fluid flow, or even develop innovative methods for simulating complex fluid systems. These simulations were generated using the Smoothed Particle Hydrodynamics (SPH) method, where fluid is represented as a collection of particles floating in space.
In this post, we provide an overview of our Fluid Cube dataset—a free resource you can can download today.
Fluid Cube Dataset Structure
Inside the dataset folder, you’ll find a .csv file containing the metadata for all 100 simulations. This metadata includes key fluid properties for each simulation, such as fluid viscosity, initial shape, velocity, and the corresponding simulation ID.
The outputs of each simulation are stored in a folder labeled with the respective simulation ID. Inside, you’ll find an .npy file containing the particle data for all time steps.
In addition to the simulation data, each folder also contains a video of the simulation rollout, providing a visual representation to make it easier to understand the data for each simulation.
Here’s what the file structure schema looks like:
├── sim_0000
│ ├── particle_data.npy
│ └── simulation_movie.mp4
├── ...
├── sim_0099
│ ├── particle_data.npy
│ └── simulation_movie.mp4
└── summary.csv
Included with the dataset is a Jupyter notebook that provides instructions on how to load each simulation file and access the particle positions and velocities data.
Ideas for Using the Fluid Cube Dataset
This fluid cube dataset offers several exciting applications, including:
- Computing dynamical metrics: Analyze time-dependent metrics such as average particle velocity or force ratios, and explore their relationships with other dataset variables like viscosity and volume.
- Training machine learning models: Use the dataset to train models that can learn and predict fluid dynamics behavior across different simulation scenarios.
🌊 Have fun! 🌊
If you have any doubts regarding the dataset, don’t hesitate to reach out at datasets@inductiva.ai! Also, if you’re using this data in your projects, we’d love to hear about it! We’ve got other cool datasets too, like our Simulated Structural Parts Dataset (SimuStruct), which is also available to download.
Curious about creating your own synthetic datasets? Check out our own recipe for generating synthetic datasets to train physics-based ML models using Inductiva’s API!
Get started now and try our API for free.


