OpenFOAM-Foundation
OpenFOAM-Foundation runs MPI without extra flags, meaning MPI enforces a strict rule: the number of processes requested must be less than or equal to the number of physical CPU cores available.
For example, on a c2d-highcpu-16 machine, which has 8 physical cores and 16 vCPUs, MPI allows at most 8 processes. This restriction means your simulation domain can only be decomposed into a number of parts equal to or fewer than the physical cores on your computational resource.
Understanding the Default Behaviour
Let’s revisit the motorBike case from this tutorial. This simulation is split into 8 sub-domains, meaning it runs with 8 MPI processes.
Now, suppose we allocate this job to a cloud machine with 16 vCPUs, such as the c2d-highcpu-16 instance, which
provides 8 physical cores:
cloud_machine = inductiva.resources.MachineGroup(
provider="GCP",
machine_type="c2d-highcpu-16",
spot=True)
The computational resources are configured with threads_per_core=2 (hyper-threading enabled), which is the default setting for virtual machines on Inductiva (learn more here).
However, OpenFOAM-Foundation runs MPI with default settings, which restricts the number of MPI processes to the number of physical cores (in this case, 8). It does not make use of the second thread (hyper-thread) per core, even though hyper-threading is enabled.
As a result:
- Only 8 of the 16 vCPUs are used
- vCPU usage reaches only ~50%
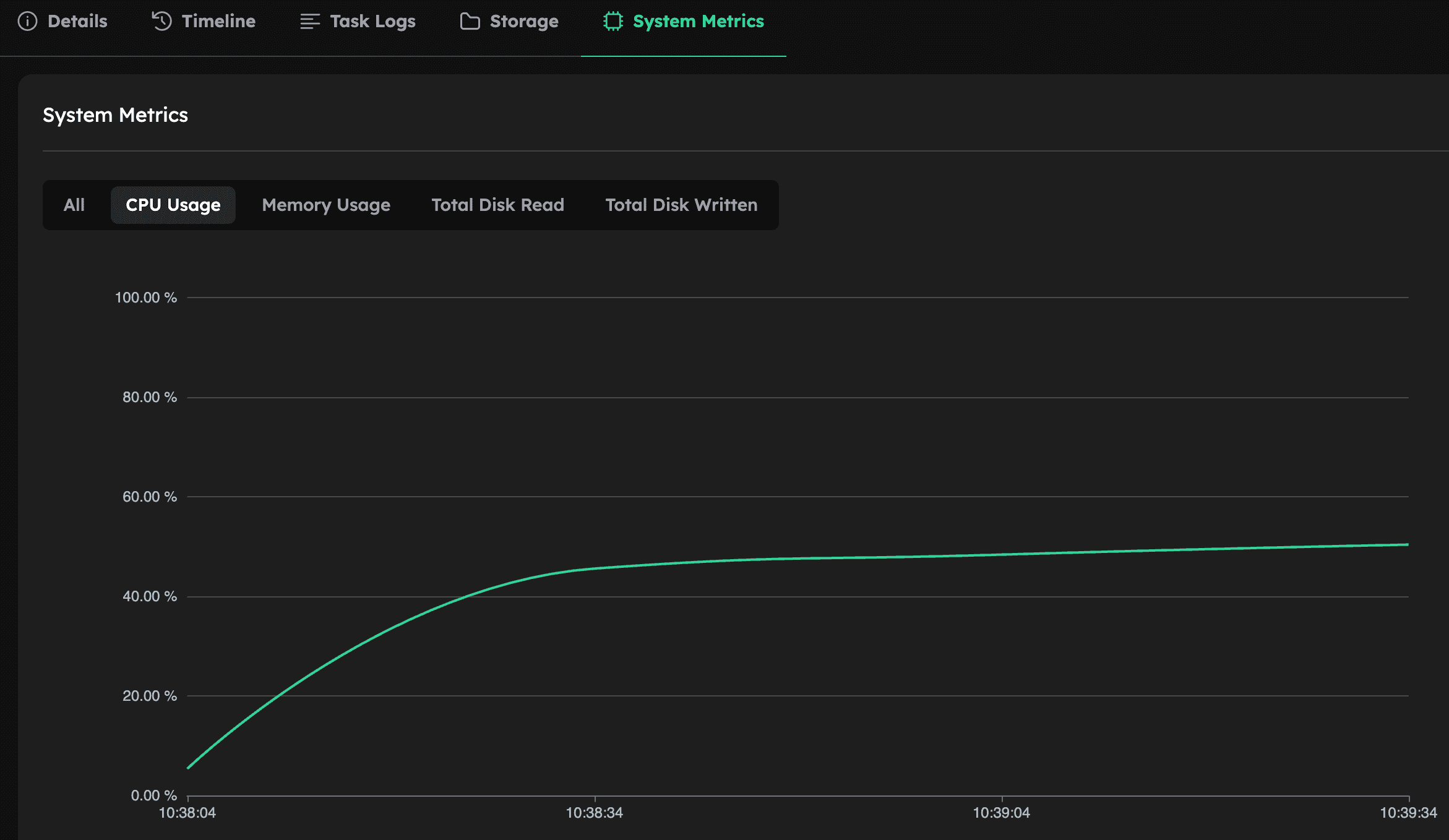
Note: In this default configuration, with hyper-threading enabled (
threads_per_core=2) but OpenFOAM running only one MPI process per physical core, seeing ~50% CPU usage does not mean the processor is underutilized. It simply reflects that OpenFOAM is using one thread per core. The actual computational resource makes full use of the underlying physical cores.
Utilize All Physical Cores
To disable hyper-threading, and thus have only one thread (vCPU) per physical core, you need to set threads_per_core=1 when starting a machine group, as shown below. Learn more about this setting here.
cloud_machine = inductiva.resources.MachineGroup(
provider="GCP",
machine_type="c2d-highcpu-16",
# 1 thread per physical core
threads_per_core=1,
spot=True
)
The c2d-highcpu-16 machine has 16 vCPUs by default (threads_per_core=2). Setting threads_per_core=1 reduces the machine to 8 vCPUs, matching the 8 physical cores — one vCPU per core. As a result, running with 8 MPI partitions will fully utilize all available compute threads/vCPUs, showing 100% CPU usage:
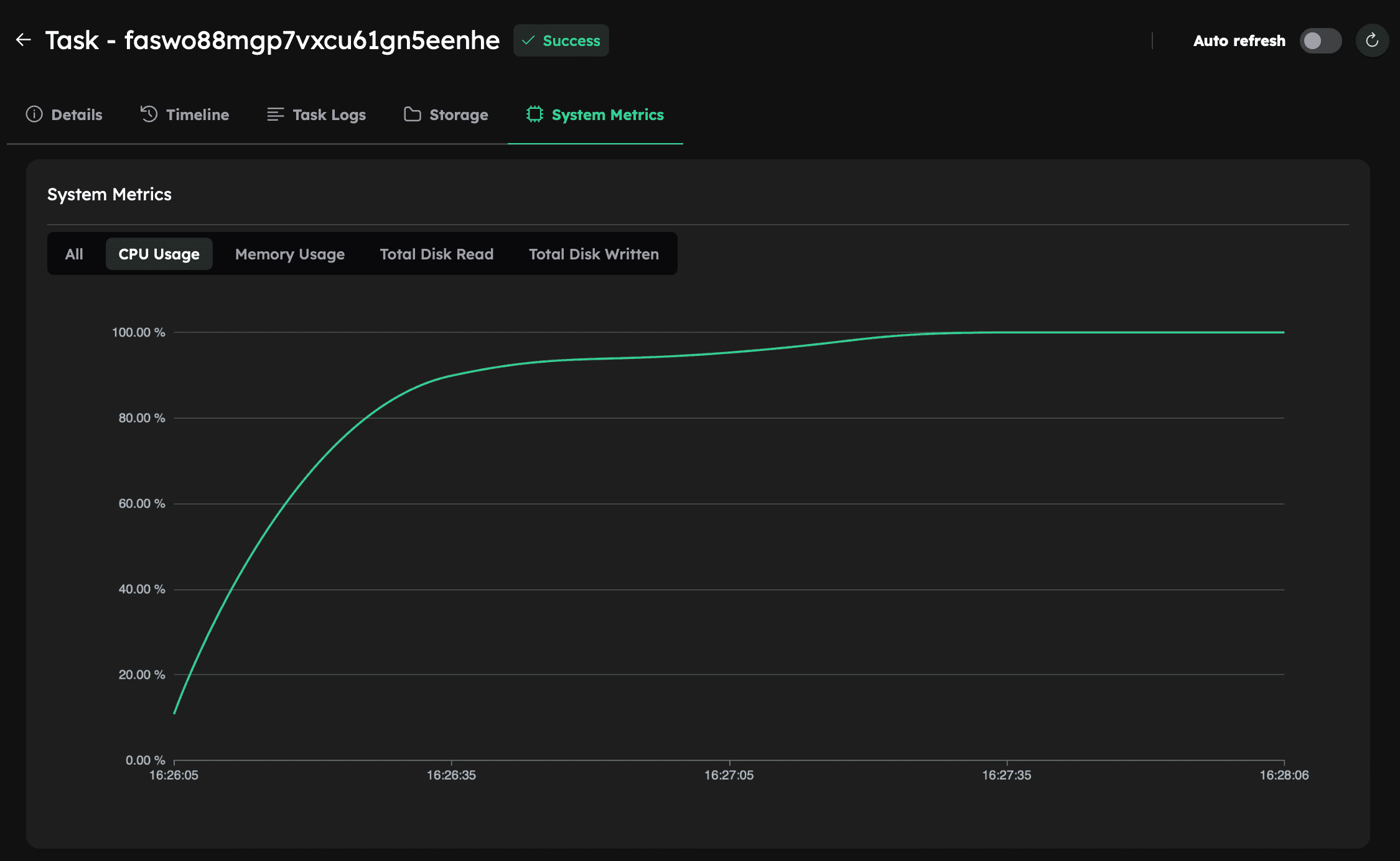
In this case, performance with hyper-threading is roughly the same because, in practice, only one thread per physical core is actively utilized in both scenarios. The difference in reported CPU usage (100% vs. ~50%) is just a reporting artifact:
- With hyper-threading enabled (
threads_per_core=2), each physical core appears as 2 vCPUs, so using only one thread per core shows ~50% usage. - With hyper-threading disabled (
threads_per_core=1), each vCPU maps directly to a core, and usage appears as 100% — even though the workload hasn’t changed.
This equivalence is confirmed by comparing the runtimes of both simulations, which are nearly identical:
| Machine Type | Threads per Core | vCPUs Available | MPI Procs | Execution Time | Estimated Cost (USD) |
|---|---|---|---|---|---|
| c2d-highcpu-16 | 1 | 8 | 8 | 1 min, 58s | 0.0026 |
| c2d-highcpu-16 | 2 | 16 | 8 | 1 min, 56s | 0.0025 |
Enable Full vCPU Usage with Hyper-Threading
You can override OpenFOAM-Foundation’s default MPI behaviour to run across all available vCPUs, which is 16 on the c2d-highcpu-16 instance with hyper-threading enabled.
To do this, update the Allrun script by replacing each runParallel call with:
mpirun -np 16 --use-hwthread-cpus <command> -parallel
Make sure to include the -parallel flag after the OpenFOAM command.
By explicitly allowing MPI to use all hardware threads, you achieve near 100% CPU utilization across all 16 vCPUs:
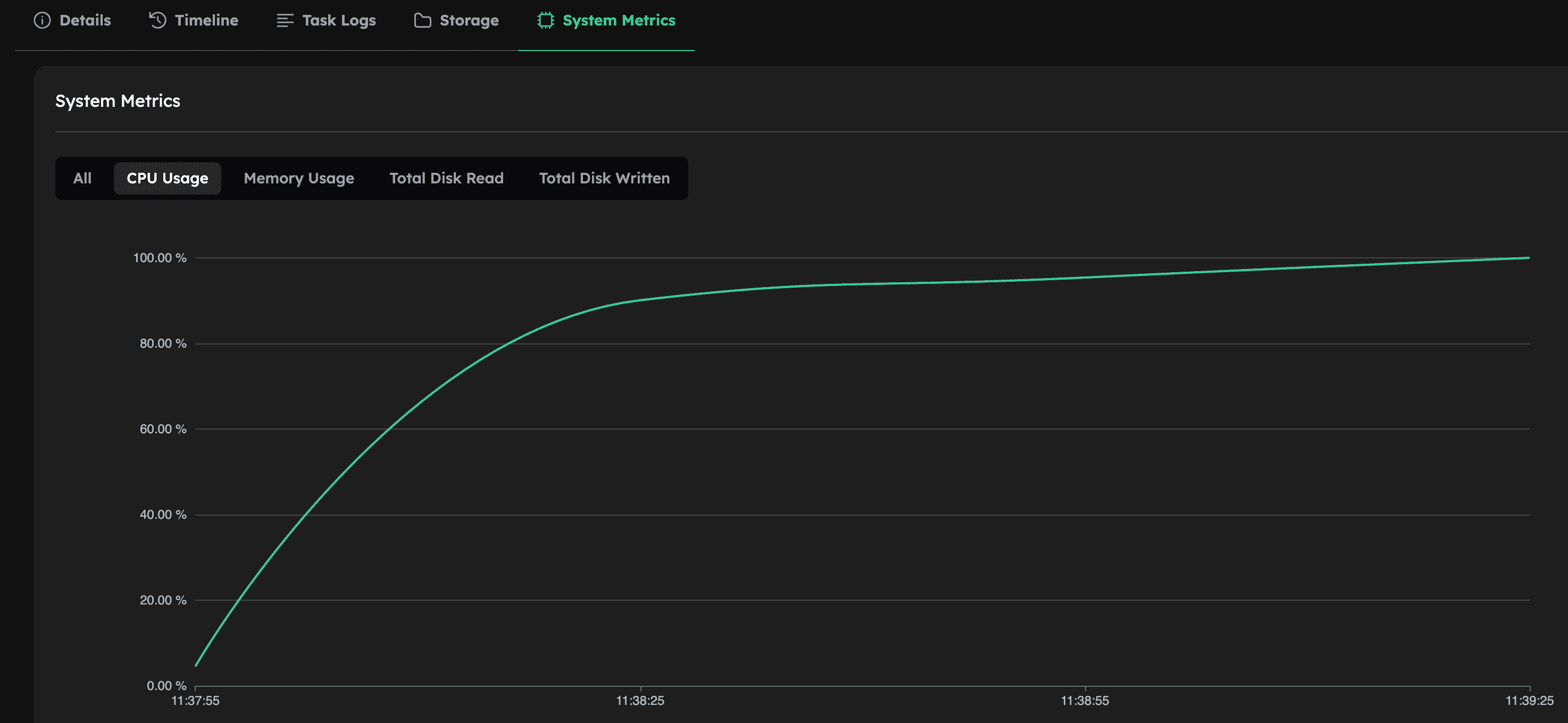
As shown below, the runtime and cost are still similar to the previous configurations, showing that while more vCPUs are utilized, the overall performance gain may be modest depending on the workload.
| Machine Type | Threads per Core | vCPUs Available | MPI Procs | Execution Time | Estimated Cost (USD) |
|---|---|---|---|---|---|
| c2d-highcpu-16 | 2 | 16 | 16 | 1 min, 53s | 0.0025 |
Next, we’ll apply the same approaches to a larger, more realistic simulation.
Large-Scale Example: Steady-State CFD Simulation of Wind Flow in the Perdigão Region
To explore how OpenFOAM scales in a more realistic scenario, we ran a steady-state CFD simulation of the Perdigão region in Portugal. This area is known for its two parallel ridgelines, which create intricate wind flow patterns and have made it a reference location for atmospheric research.
The simulation was carried out with OpenFOAM’s simpleFoam solver on a structured, terrain-following graded mesh containing 14 million cells. The computational domain covered 30 × 30 × 3 km, with idealized atmospheric boundary layer (ABL) conditions at the inlet. Turbulence was modeled using the k–ε closure model, and we applied a stepped first- to second-order convection scheme to improve solution accuracy and convergence.
Performance Comparison
We ran these tests to understand how hyperthreading and machine size affect OpenFOAM performance and cost. Specifically, we wanted to see whether it was better to:
- (1st row) stick to physical cores on a large machine with hyperthreading enabled,
- (2nd row) try to exploit all vCPUs (logical cores) on the same large machine,
- (3rd row) disable hyperthreading and use only physical cores on the large machine, or
- (4th row) use a smaller machine with fewer physical cores to reduce cost at the expense of runtime.
Below are the results:
| Machine Type | Threads per Core | vCPUs Available | MPI Procs | Execution Time | Estimated Cost (USD) |
|---|---|---|---|---|---|
| c4d-highcpu-96 | 2 | 96 | 48 | 9h, 20 min | 15.48 |
| c4d-highcpu-96 | 2 | 96 | 96 | 10h, 58 min | 18.21 |
| c4d-highcpu-96 | 1 | 48 | 48 | 9h, 23 min | 15.58 |
| c4d-highcpu-48 | 2 | 48 | 48 | 19h, 8 min | 15.93 |
Insights
The first configuration (48 MPI ranks on 96 vCPUs with hyper-threading enabled) follows the standard OpenFOAM-Foundation practice of mapping one rank per physical core. This resulted in the fastest and most cost-effective runtime of 9h, 20 min and US$15.48.
In the second run, we increased the number of MPI ranks to 96 to fully utilize all available vCPUs. The idea was to test whether fully loading the hyperthreaded machine would improve throughput. Instead, runtime increased to 10h, 58 min, demonstrating that oversubscribing hyperthreaded cores adds contention and communication overhead, which reduces efficiency.
For the third run, we disabled hyper-threading (threads_per_core=1), limiting the machine to 48 vCPUs corresponding exactly to the 48 physical cores. The runtime (9h, 23 min) was nearly identical to the first case, confirming that explicitly turning off hyper-threading does not provide a performance benefit.
Finally, we tested a smaller instance (c4d-highcpu-48) with 48 vCPUs, which map to only 24 physical cores. Running 48 MPI ranks on this machine oversubscribed the hardware. Although the hourly cost was lower, the runtime increased to 19h 8min, resulting in a slightly higher total cost compared to the larger instance, making this option both slower and more expensive.
In summary: the best strategy seems to be running one MPI rank per physical core. Hyper-threading does not provide a measurable benefit for this workload, while trying to use all logical cores or relying on smaller hyperthreaded instances leads to poorer performance and, in some cases, higher costs.