Run All Simulations from Scenario S2_f5 in Parallel
Earlier, we explored how to run a single simulation and evaluated how hyper-threading influences SWAN simulations. Now, let’s take it a step further: we’ll run all simulations within the S2_f5 scenario in parallel.
This section demonstrates how easily you can execute an entire scenario using a single script with Inductiva.
Save the following code as a .py file inside the tutorial directory before running it.
"""SWAN Parallel Simulations example"""
import inductiva
# 1. Create a Project to group all related tasks
my_project = inductiva.projects.Project("polynya2D_runs")
# 2. Configure and Run Each Polynya Event
# Define polynya event dates
dates_to_run = [
"20161005",
"20161024",
"20201026",
"20161006",
"20190919",
"20211007",
"20161017",
"20190929",
"20161022",
"20201019"]
# Create an elastic machine group for parallel execution
cloud_machines = inductiva.resources.ElasticMachineGroup( \
provider="GCP",
machine_type="c4d-highcpu-32",
min_machines=1,
max_machines=len(dates_to_run),
data_disk_gb=20,
spot=True)
# Run each polynya event
for date in dates_to_run:
filename = f"S2_f5/polynya2D_{date}.swn"
print(f"Processing {filename}")
# Initialize the Simulator
swan = inductiva.simulators.SWAN(\
version="41.45")
# Submit a simulation task
task = swan.run(input_dir="polynya",
sim_config_filename=filename,
resubmit_on_preemption=True,
on=cloud_machines)
# Add task to project and store metadata for later
my_project.add_task(task)
task.set_metadata({
"date": date,
"filename": filename
})
# 3. Wait for all simulations to complete
my_project.wait()
cloud_machines.terminate()
# (You can safely close your laptop and let Inductiva handle the rest!)
We're going to break down each portion of the code for better understanding.
1. Create an Inductiva Project
Each task in this example represents a polynya event. To keep things organized, all tasks are grouped under a single Project.
Learn more about
Projectshere.
2. Configure and Run Each Polynya Event
To run tasks in parallel, we use an ElasticMachineGroup. Unlike the default MachineGroup, this class automatically scales between a defined minimum and maximum number of machines based on workload.
In this case, the maximum number of machines equals the number of polynya events in the S2_f5 scenario.
This elasticity ensures efficient use of resources: faster tasks don’t have to wait for slower ones, and idle machines automatically shut down when no simulations are left in the queue. As a result, your computational resources stay optimized.
Learn more about the
ElasticMachineGroupclass here.
Since we’re using spot machines, simulations might occasionally be interrupted if reclaimed by the cloud provider. However, by enabling resubmit_on_preemption=True, any interrupted tasks are automatically retried. You can read more about this in Understanding Preemption.
Within the loop, each simulation is submitted, and metadata (such as event date and filename) is stored for easy reference later.
3. Wait for All Simulations to Finish
Once all simulations have finished, the machine group is terminated and results are retrieved.
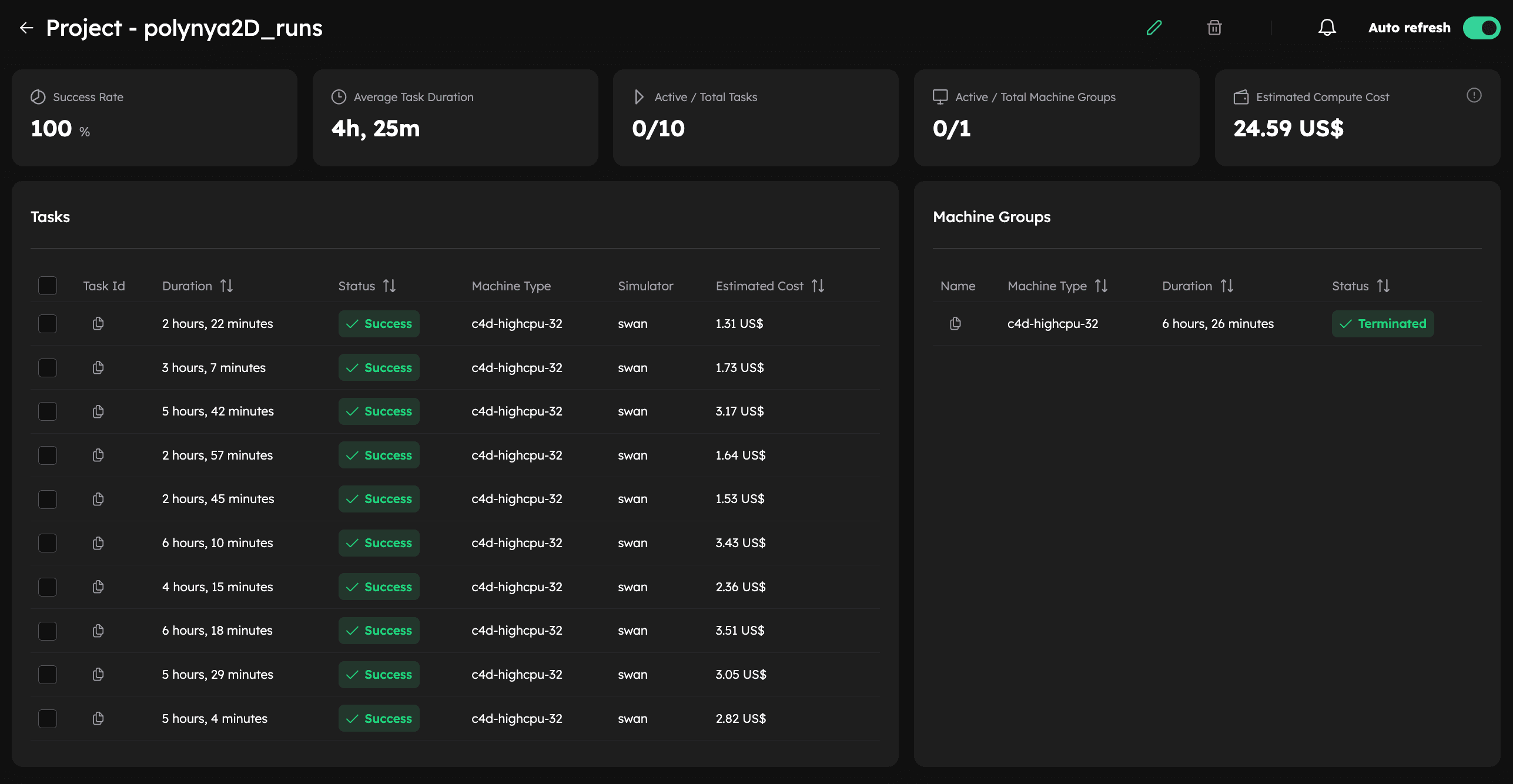
You can monitor your project and all associated tasks in the Inductiva Console, as illustrated below:
Summary
By leveraging Inductiva’s platform, you can:
- Launch an entire scenario’s simulations in parallel
- Save time and simplify large-scale workflows
In just a few lines of code, you’ve gone from running a single simulation to executing an entire scenario. ⚡️