Leverage the power of high-performance computing in minutes.
Results and Key Takeaways
We successfully generated a TurbSim dataset in parallel by sampling the seeds and the wind speed. This demonstrates the power of using cloud resources to efficiently scale up computational experiments. Now it's time to retrieve all the results and analyze the data to extract meaningful insights from our simulations.
Project Summary and Output Download
Using the Inductiva package, it is easy to get a project summary and download all the output files. The following code snippet demonstrates how to do this:
import inductiva
turbsim_project = inductiva.projects.Project(
name="turbsim_dataset")
print(turbsim_project)
turbsim_project.download_outputs()
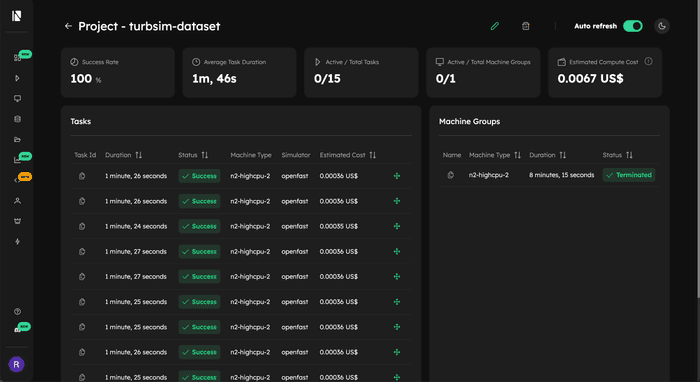
Executing print(turbsim_project) gives a summary of the main project details:
Project 'turbsim_dataset' created at 2025-05-16 14:50.
Total number of tasks: 25
Tasks by status:
success: 25
Estimated total computation cost: 0.0067 US$
Running openfast_project.download_outputs() creates a folder called inductiva_output/turbsim_project with one folder for each simulation.
The project information is also available on the Inductiva Web Console on the projects tab:
Retrieve Task Metadata
Retrieving the previously set metadata is easy with the Inductiva API. Below we show how you can retrieve the metadata of all the tasks in the project:
import inductiva
turbsim_project = inductiva.projects.Project(
name="turbsim_dataset")
for task in turbsim_project.get_tasks():
print(f"Task ID: {task.id}")
print(f"Task metadata: {task.get_metadata()}")
print()
Task ID: 37a3qp59b11g2kjvhttuhh004
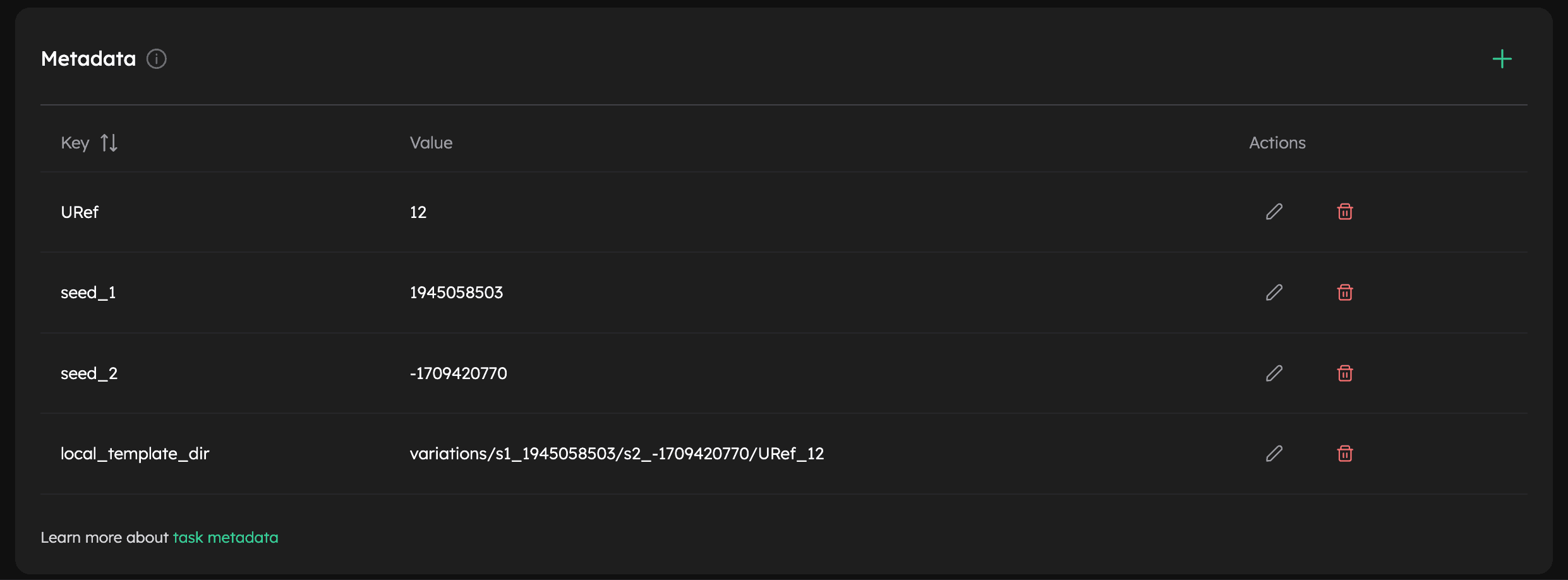
Task metadata: {'URef': '12', 'seed_1': '1945058503', 'seed_2': '-1709420770', 'local_template_dir': 'variations/s1_1945058503/s2_-1709420770/URef_12'}
Task ID: 88c0w2bigcaim0bwdzejitsth
Task metadata: {'URef': '12', 'seed_1': '144736085', 'seed_2': '-2036154925', 'local_template_dir': 'variations/s1_144736085/s2_-2036154925/URef_12'}
Task ID: 1vp0ajszufcang0qct0vt2ytb
Task metadata: {'URef': '13', 'seed_1': '-124466270', 'seed_2': '-864712422', 'local_template_dir': 'variations/s1_-124466270/s2_-864712422/URef_13'}
...
You can also check the task metadata on the Inductiva Web Console:
Key Takeaways
In summary, using cloud computing for generating datasets of large-scale simulations not only increases efficiency, but also significantly reduces computational time and cost. By running 25 simulations in parallel, we were able to overcome one of the limitations of TurbSim, which is that it does not scale with multiple CPU cores.
Inductiva makes it possible and convenient to run hundreds or thousands of simulations. For example, you could now change the code for:
- Cover a design space with many more parameters;
- Add a black-box optimizer, such as Vizier, on top of the loop and add an evaluation function to analyse the result of each completed simulation and perform an intelligent exploration of the design space;
- Build a really large dataset of example simulations to later train a surrogate model.
Inductiva can simplify research by making high-performance computing more accessible and cost-effective.